A Quick Case Study on Contributing to Dagster
Monday, March 17, 2025
Introduction
Over the last couple of months, I became a contributor to Dagster. While working on one of the issues for the project, my first major challenge involved wrestling with a confusing bug in the codebase. I saw how a single unexpected issue could cause a domino effect for the entire team, and I decided to document my journey. In this article, I'll walk you through my experience with Dagster, how we tackled the thorny code problem, and why maintaining readable code matters so much in open source projects.
The Codebase / Product
Dagster is a powerful data orchestration framework that aims to make data engineering workflows more modular and robust. Dagster serves 800 active companies with 50-200 employees & $10M-50M in revenue.
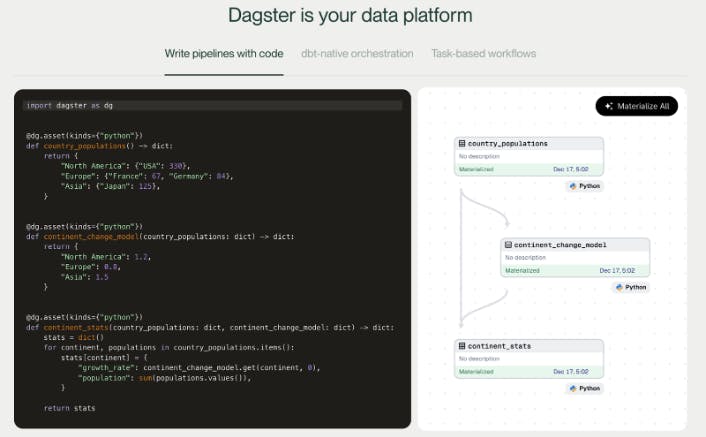
The motivation driving the creation of Dagster stems from a genuine desire to cater to the specific needs of businesses. For some time, business owners have sought a comprehensive solution to gain a bird's-eye view of their company's progress through Dagster. Ship data pipelines quickly and confidently with the modern data orchestrator built for data engineers building data platforms.. This powerful tool equips data engineers with real-time insights, enabling them to expertly guide data towards successful production phases. Below you will find some screenshots of the MVP in action.
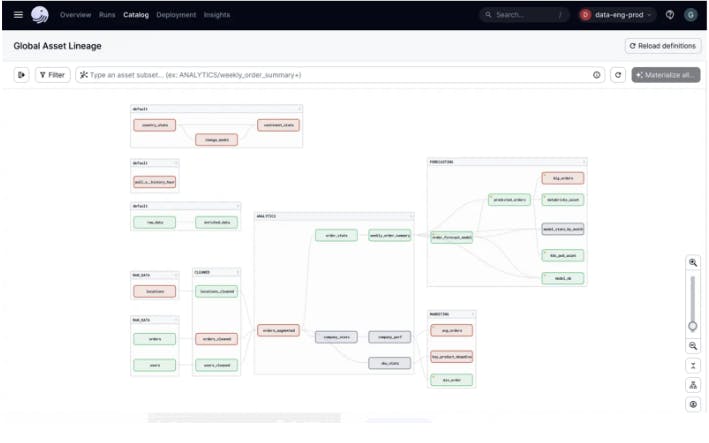
The diagram on the right illustrates how these assets connect, with the final asset merging data from the first two..
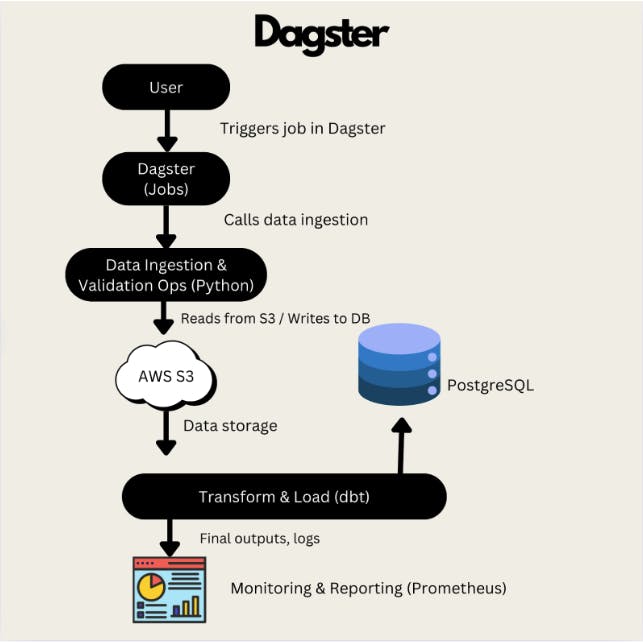
System Overview
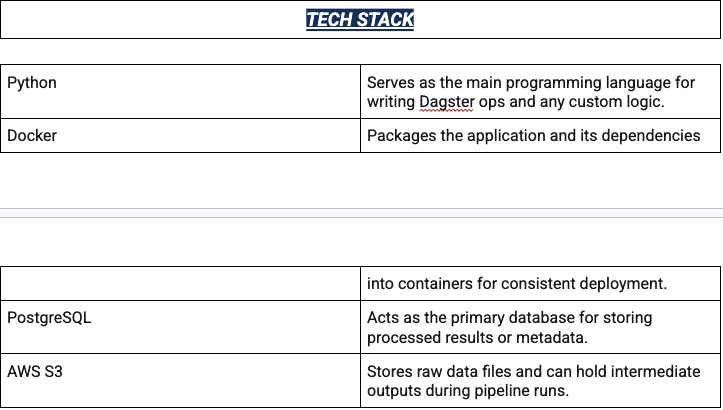
Before delving into how the issue was solved, let's first examine the project's current functionality. Below, you'll find a system design diagram followed by the tech stack and flow of control that will aid in breaking down the functionality at a higher level.